A Comprehensive and Detailed Introduction to YOLOv8
It's no secret that YOLO models have revolutionized the field of Computer Vision. Identifying objects is a crucial task in computer vision that finds its application in several fields like robotics, medical imaging, surveillance systems, and autonomous vehicles. The newest version of the YOLO model, YOLOv8, which is an advanced real-time object detection framework, has attracted the attention of the research community. Of all the popular object recognition machine learning models such as Faster R-CNN, SSD, and RetinaNet, YOLO is the most popular in terms of accuracy, speed, and efficiency.
Introduction to YOLOv8
What is YOLOv8?
YOLO is an object detection algorithm that excels in speed and accuracy. YOLO v8, short for You Only Look Once version 8, represents the latest advancements in the series. It is a state-of-the-art system that marries computer vision with deep learning. This synergy marks a huge advancement in finding, classifying, and breaking down digital visuals. Traditional detection models often involve a two-step process: first identifying regions of interest and then classifying those regions. In contrast, YOLO innovated by predicting both the classifications and bounding boxes in one single pass through the neural network, significantly speeding up the process and improving real-time detection capabilities.

| Is YOLOv8 Open Source? | Who is the Author of YOLOv8? | When Was YOLOv8 Released? | |
| Q&A | YOLOv8 is an Open Source SOTA model built and maintained by the Ultralytics team. It is distributed under the GNU General Public License, which authorizes the user to freely share, modify and distribute the software. | YOLOv8 is written and maintained by the Ultralytics team. YOLO models were initially created by Joseph Redmon, a Computer Scientist. He cycled through three iterations of YOLO, with the third one being YOLOv3, all written in Darknet Architecture. Glenn Jocher shadowed YOLOv3 in PyTorch along with a few minor changes and named it YOLOv5. YOLOv5’s architecture was then modified to develop YOLOv8. | YOLOv8 was officially released on January 10th, 2023. As of writing, it is still under active development. |
What's New in Yolov8?
It is an advanced model that improves upon the success of YOLOv5 by incorporating modifications that enhance its power and user-friendliness in various computer vision tasks. These enhancements include a modified backbone network, an anchor-free detection head and multi-scaled object detection . Furthermore, it provides built-in support for image classification tasks. YOLOv8 is distinctive in that it delivers unmatched speed and accuracy performance while maintaining a streamlined design that makes it suitable for different applications and easy to adapt to various hardware platforms.
Architecture Advancement
Backbone
YOLOv8 features a new backbone network which is a modified version of the CSPDarknet53 architecture which consists of 53 convolutional layers and employs a technique called cross-stage partial connections to enhance 6 the transmission of information across the various levels of the network. This Backbone of YOLOv8 consists of multiple convolutional layers organized in a sequential manner that extract relevant features from the input image.

Head
The head of YOLOv8 comprises multiple convolutional layers followed by fully connected layers, responsible for predicting bounding boxes, objectness scores, and class probabilities for detected objects in an image.
An essential feature of YOLOv8 is the incorporation of a self-attention mechanism in the network's head, enabling the model to selectively attend to different areas of the image and adjust the importance of features based on their relevance to the task.
Anchor-Free Detection
Similar to YOLOv6 and YOLOv7, YOLOv8 is a model that does not rely on anchors. This means that it predicts the centre of an object directly rather than the offset from a known anchor box. Anchor boxes were a well-known challenging aspect of early YOLO models (YOLOv5 and earlier) since these could represent the target benchmark's box distribution but not the distribution of the custom dataset. The use of anchor-free detection minimises the number of box predictions, which speeds up Non-Maximum Suppression (NMS), a complex post-processing phase that sifts through candidate detections following inference.
Multi-scaled Object Detection
YOLOv8 excels in multi-scaled object detection by employing a feature pyramid network to identify objects of various sizes and scales within an image. This network includes multiple layers designed to detect objects at different scales, enabling the model to identify both large and small objects within an image.
Other Advancements in Computer Vision
Efficient segmentation capability
The YOLOv8 model also excels in segmentation tasks, a critical aspect of computer vision. Whether it’s for object detection or instance segmentation or more general segmentation models, YOLOv8, especially the YOLOv8 Nano model, demonstrates a remarkable proficiency. Its ability to precisely segment and classify different parts of an image makes it highly effective in diverse applications, from medical imaging to autonomous vehicle navigation.
Python Integration Advantage
Another key aspect of YOLOv8 is its Python package, which facilitates easy integration and use in Python-based projects. This accessibility is crucial, especially considering Python’s popularity in the data science and machine learning communities. Developers can train a YOLOv8 model on a custom dataset using PyTorch, a leading deep learning framework. This flexibility allows for tailored solutions to specific computer vision challenges.
Main Functions of YOLOv8
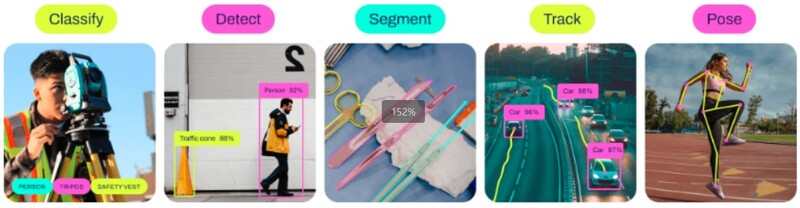
Yolov8 is the latest version of YOLO by Ultralytics. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports a full range of vision AI tasks, including detection, segmentation, pose estimation, tracking, and classification. This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains
- Object detection, as a computer vision task, aims to locate and identify objects within an image or video stream. The task involves identifying the position and boundaries of objects in the image, as well as categorizing the objects into different classes 1. The output of an object detector consists of bounding boxes around the detected objects, along with class labels and confidence scores for each box. This approach is particularly useful when the precise location or shape of the object is not required, but rather the focus is on identifying the presence of objects within a scene.

- Instance segmentation goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image. The output of an instance segmentation model is a set of masks or contours that outline each object in the image, along with class labels and confidence scores for each object. Instance segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.

- Pose estimation involves identifying specific points in an image referred to as keypoints, representing different parts of an object, with outputs being coordinates and confidence scores for each point, useful for locating and understanding object parts in a scene.
- Object tracking in the realm of video analytics is a critical task that not only identifies the location and class of objects within the frame but also maintains a unique ID for each detected object as the video progresses. The applications are limitless—ranging from surveillance and security to real-time sports analytics.

- Image classification is the simplest of the three tasks and involves classifying an entire image into one of a set of predefined classes. The output of an image classifier is a single class label and a confidence score. Image classification is useful when you need to know only what class an image belongs to and don't need to know where objects of that class are located or what their exact shape is.
Key Features of YOLOv8
Multiple features are to be focused on YOLOv8. Here are some key features of YOLOv8:
- Enhanced Accuracy: YOLOv8 has a high rate of accuracy measured by Microsoft COCO and Roboflow 100. YOLOv8 achieves strong accuracy on COCO. For example, the YOLOv8m model -- the medium model -- achieves a 50.2% mAP when measured on COCO. When evaluated against Roboflow 100, a dataset that specifically evaluates model performance on various task-specific domains, YOLOv8 scored substantially better than YOLOv5.
- Improved Efficiency: YOLOv8 introduces multi-scale object detection and the ELU activation function, improving the model's performance and convergence speed. ELU (Exponential Linear Unit) accelerates learning in deep neural networks by alleviating the vanishing gradient problem, leading to faster convergence. Additionally, it adopts the GIoU (Generalized Intersection over Union) loss to enhance object localization accuracy. Compared to YOLOv7, YOLOv8 achieves a 1.2% increase in average precision, while reducing the model's weight file size by 80.6 megabytes, making it more efficient and easier to deploy in resource-constrained environments.

YOLOv8 Comparison with Latest YOLO models
- Enhanced Inference Speed: Integrating Neural Magic’s DeepSparse with YOLOv8, YOLOv8 achieves up to 525 FPS (on YOLOv8n), significantly speeding up YOLOv8's inference capabilities compared to traditional methods.

- Optimized Model Efficiency: Uses pruning and quantization to enhance YOLOv8's efficiency, reducing model size and computational requirements while maintaining accuracy.

- Developer-convenience: As opposed to other models where tasks are split across many different Python files that you can execute, YOLOv8 comes with a CLI that makes training a model more intuitive. This is in addition to a Python package that provides a more seamless coding experience than prior models.
Potential Use Cases of YOLOv8
Here are some potential use cases for YOLOv8:
Object Detection in Surveillance Systems
YOLOv8 can be utilized for real-time object detection in surveillance systems, enabling the identification of persons, vehicles, or other relevant objects within a monitored area.
Autonomous Vehicles and Traffic Management
YOLOv8's real-time multi-scaled object detection capabilities make it suitable for integration into autonomous vehicles and traffic management systems. It can aid in identifying pedestrians, vehicles, road signs, and traffic signals.
Industrial Quality Control
YOLOv8 can be used for quality control in manufacturing processes. It can identify and inspect products, defects, or anomalies on production lines, ensuring product quality and safety.
Retail Analytics and Inventory Management
In retail environments, YOLOv8 can facilitate various applications such as customer tracking, queue monitoring, inventory management, and theft prevention through real-time object detection.

Healthcare Applications
YOLOv8's object detection capabilities can be deployed in healthcare settings for tasks such as patient monitoring, medical image analysis, and identifying medical equipment within hospital environments.
Environmental Monitoring
YOLOv8 can contribute to environmental monitoring by identifying and tracking wildlife, assessing land cover changes, monitoring natural disasters, and more.
Agriculture Monitoring
YOLOv8 can track crop growth, detect crop diseases, and recognize pests. It can also facilitate precision agriculture by identifying areas of a field that require varying degrees of water or fertilizer. By providing faster and more precise data, YOLOv8 can support farmers in making more informed decisions, increasing crop yields, and decreasing waste.
Challenges in Using YOLOv8
Training Data Limitations
While YOLO v8 performs exceptionally well on standard datasets, its accuracy can be compromised when faced with unique or highly specialized scenarios. The model heavily relies on the quality and diversity of training data, and ensuring comprehensive coverage remains a challenge.
Small Object Detection
YOLO v8 may struggle with the detection of small objects in images. Objects with minimal pixel dimensions pose a challenge as the model’s receptive field may not capture sufficient details, impacting accuracy in such scenarios.

Resource Intensiveness
The high computational requirements of YOLO v8 can be a hindrance, especially in resource-constrained environments. Training the model demands powerful GPUs, and deploying it on edge devices may require optimizations to ensure real-time performance without compromising accuracy.
Limited Context Understanding
YOLO v8 processes the entire image at once, lacking contextual understanding between different regions. This can lead to misinterpretations, especially in scenes where the relationships between objects are crucial for accurate detection.
Adversarial Attacks
Like many deep learning models, YOLO v8 is susceptible to adversarial attacks. Minor perturbations in input images can lead to misclassifications or false detections, raising concerns about the model’s robustness in security-sensitive applications.
Conclusion
YOLO v8 incorporates cutting-edge techniques that have been shown to improve object detection accuracy and speed while reducing computation and memory requirements, such as the addition of attention modules and self-attention mechanisms and the use of spatial pyramid pooling and deformable convolutions. Overall, YOLO v8 exhibits great potential as an object detection model that can enhance real-time detection capabilities. This latest version of YOLO is a notable advancement in the realm of computer vision and is likely to stimulate additional exploration and progress in this domain.
Related Article:
Run YOLOv8 on LattePanda Mu (Intel N100 processor) with OpenVINO

Discover how the YOLO model is transforming industries with its real-time object detection capabilities. Explore its applications in autonomous driving, smart surveillance, manufacturing, and precision agriculture.
NEWS
DFRobot is heading to Embedded World 2025 in Nuremberg, Germany, from March 11-13, and we’re bringing the latest in embedded computing, IoT, and industrial solutions.
NEWS
This article introduces the Mind+(Mindplus) editor, which seamlessly combines block-based and text coding in its interface, facilitating an easier transition.
NEWS
I3C improves on I2C with faster speeds, better power efficiency, and advanced features, unlocking greater potential for future embedded systems.
NEWS